GMP 模型

1.前言
1.1 线程模型
- 内核级线程(Kernel Level Thread)模型
- 用户级线程(User Level Thread)模型
- 两级线程模型(混合型线程模型)
1.2 ULT vs KLT
| 特性 | 用户级线程 | 内核级线程 |
|---|---|---|
| 创建者 | 应用程序 | 内核 |
| 操作系统是否感知存在 | 否 | 是 |
| 开销成本 | 创建成本低,上下文切换成本低,上下文切换不需要硬件支持。 | 创建成本高,上下文切换成本高,上下文切换需要硬件支持。 |
| 如果线程阻塞 | 整个进程将被阻塞,即不能利用多处理来发挥并发优势。 | 其它线程可以继续执行,进程不会阻塞。 |
| 案例 | Java thread,POSIX threads | Windows Solaris |
1.3 内核级线程模型
内核级线程模型中用户线程与内核线程是一对一关系(1 : 1)。线程的创建、销毁、切换工作都是有内核完成的。应用程序不参与线程的管理工作,只能调用内核级线程编程接口(应用程序创建一个新线程或撤销一个已有线程时,都会进行一个系统调用)。每个用户线程都会被绑定到一个内核线程。用户线程在其生命期内都会绑定到该内核线程。一旦用户线程终止,两个线程都将离开系统。
1.4 用户级线程模型
用户线程模型中的用户线程与内核线程KSE是多对一关系(N : 1)。线程的创建、销毁以及线程之间的协调、同步等工作都是在用户态完成,具体来说就是由应用程序的线程库来完成。内核对这些是无感知的,内核此时的调度都是基于进程的。线程的并发处理从宏观来看,任意时刻每个进程只能够有一个线程在运行,且只有一个处理器内核会被分配给该进程。
1.5 两级线程模型
两级线程模型中用户线程与内核线程是一对一关系(N : M)。两级线程模型充分吸收上面两种模型的优点,尽量规避缺点。其线程创建在用户空间中完成,线程的调度和同步也在应用程序中进行。一个应用程序中的多个用户级线程被绑定到一些(小于或等于用户级线程的数目)内核级线程上。
1.6 Golang 线程模型
Golang在底层实现了混合型线程模型。M 即系统线程,由系统调用产生,一个M关联一个 KSE,即两级线程模型中的系统线程。G 为 Groutine,即两级线程模型的的应用及线程。M 与 G 的关系是 N:M。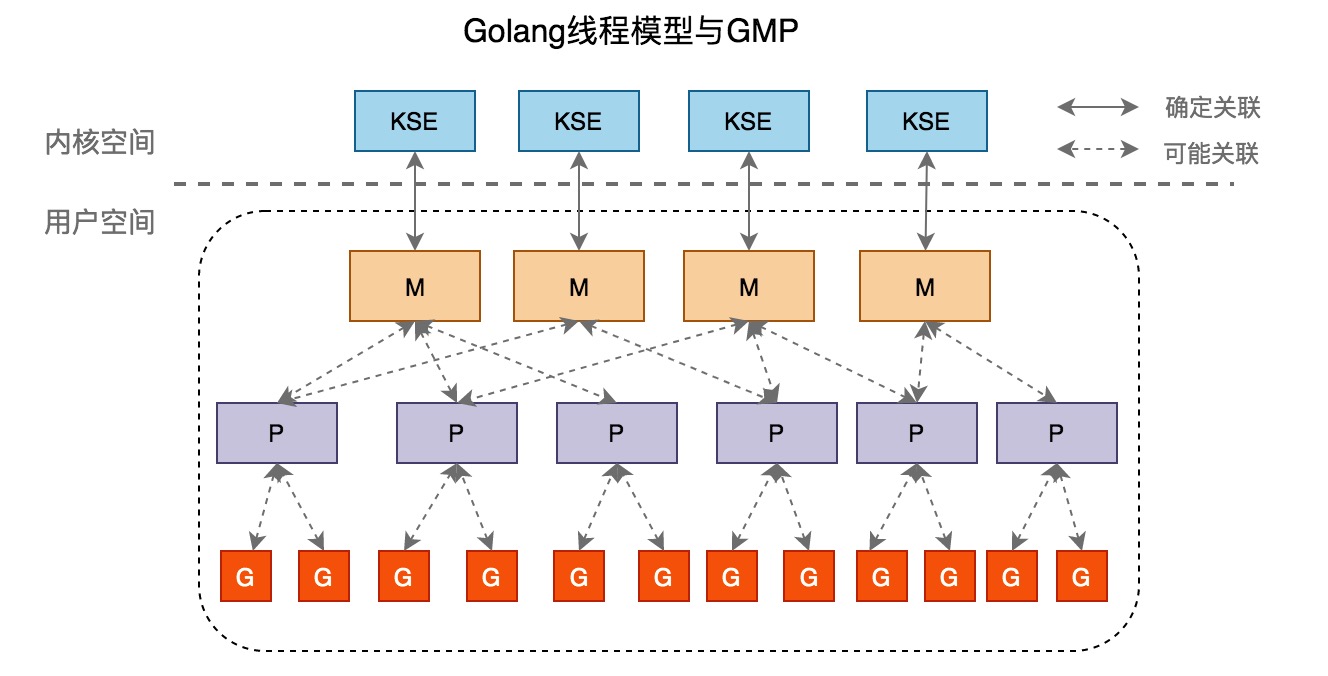
2.GMP
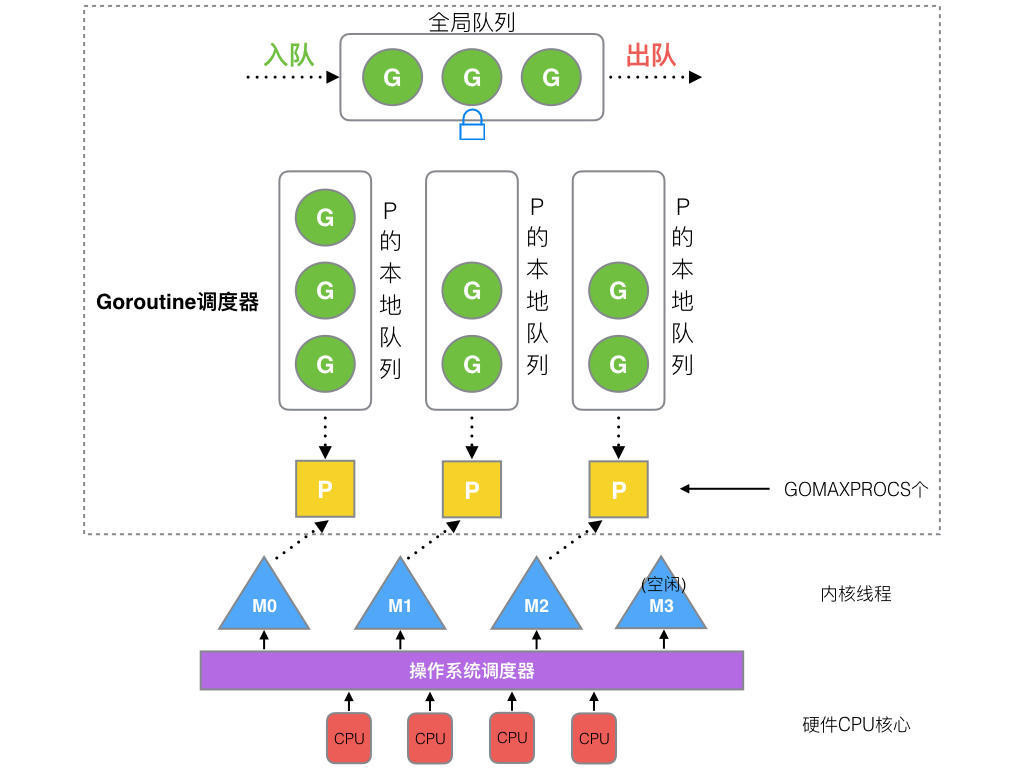
G(Goroutine):代表 Go 协程 Goroutine,存储了 Goroutine 的执行栈信息、Goroutine 状态以及 Goroutine 的任务函数等。G 的数量无限制,理论上只受内存影响,创建了一个 G 的初始栈大小为 2~4K,配置一般的机器也能简单开启数十万个 Goroutine,而且 Go 语言在 G 退出的时候还会把 G 清理之后放到 P 本地或者全局的闲置列表 gFree 中以便复用。
M(Machine):Go 对操作系统线程(OS thread)的封装,可以看作操作系统内核线程,想要在 CPU 上执行代码必须有线程,通过系统调用 clone 创建。M 在绑定有效的 P 后,进入一个调度循环,而调度循环的机制大致是从 P 的本地运行队列以及全局队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。M 的数量有限制,默认数量限制是 10000,可以通过 debug.SetMaxThreads() 方法进行设置,如果有 M 空闲,那么就会回收或者睡眠。
P(Processor):虚拟处理器,M 执行 G 所需的资源和上下文,只有将 P 和 M 绑定,才能让 P 的 runq 中的 G 真正运行起来。P 的数量决定了系统内最大可并行的 G 的数量,P 的数量受本机的 CPU 核数影响,可通过环境变量 $GOMAXPROCS 或 runtime.GOMAXPROCS() 来设置,默认为 CPU 核心数。
Sched:调度器结构,维护有存储 M 和 G 的全局队列,以及调度器的一些状态信息。
| G | M | P | |
|---|---|---|---|
| 数量限制 | 无限制,受机器内存影响 | 有限制,默认最多10000 | 有限制,最多GOMAXPROCS个 |
| 创建时机 | go func | 当没有足够的M来关联P并运行其中的可运行的G时会请求创建新的M | 在确定了P的最大数量n后,运行时系统会根据这个数量创建P |