基础篇
1.MySql 执行流程
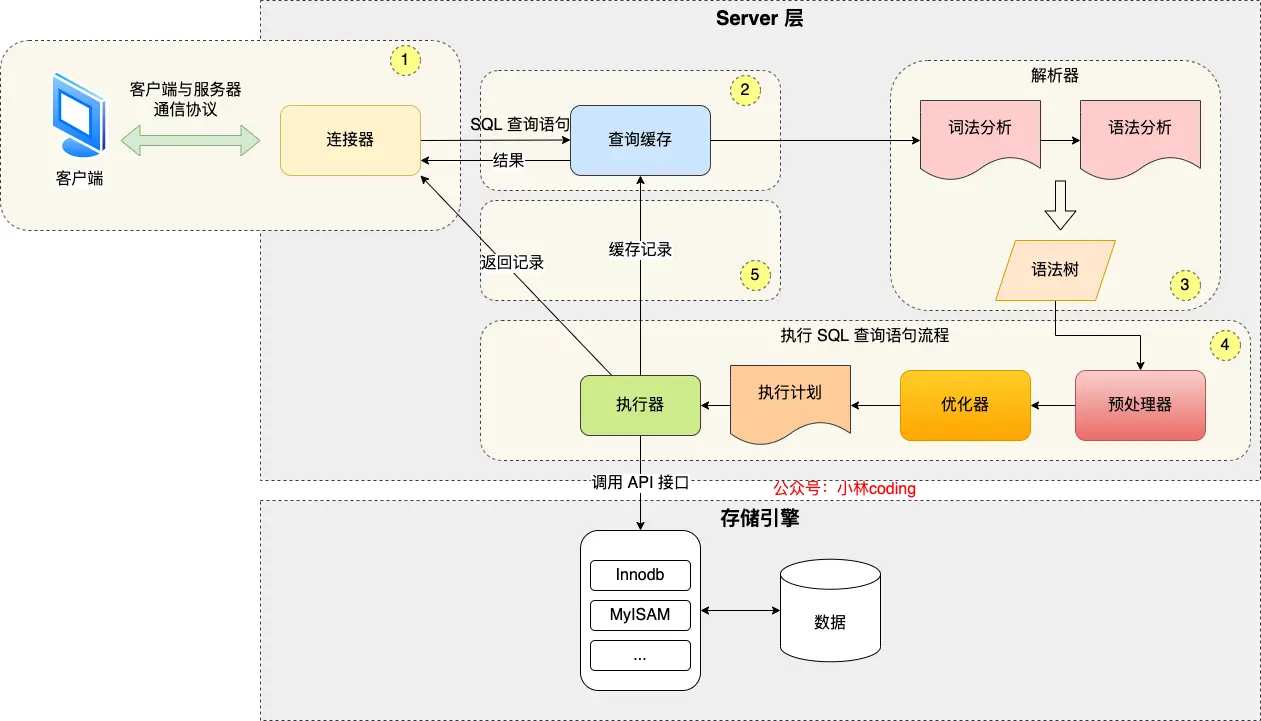
MySQL 的架构共分为两层:Server 层和 存储引擎 层:
- Server 层负责建立连接、分析和执行 SQL。MySQL 大多数的核心功能模块都在这实现,主要包括连接器,查询缓存、解析器、预处理器、优化器、执行器等。另外,所有的内置函数(如日期、时间、数学和加密函数等)和所有跨存储引擎的功能(如存储过程、触发器、视图等。)都在 Server 层实现。
- 存储引擎层负责数据的存储和提取。支持 InnoDB、MyISAM、Memory 等多个存储引擎,不同的存储引擎共用一个 Server 层。现在最常用的存储引擎是 InnoDB,从 MySQL 5.5 版本开始, InnoDB 成为了 MySQL 的默认存储引擎。常说的索引数据结构,就是由存储引擎层实现的,不同的存储引擎支持的索引类型也不相同,比如 InnoDB 支持索引类型是
B+树 ,且是默认使用,也就是说在数据表中创建的主键索引和二级索引默认使用的是B+树索引。
2.如何存储一行记录
2.1 表空间文件的结构
表空间由 段 segment、区 extent、页 page、行 row 组成,InnoDB 存储引擎的逻辑存储结构大致如下图: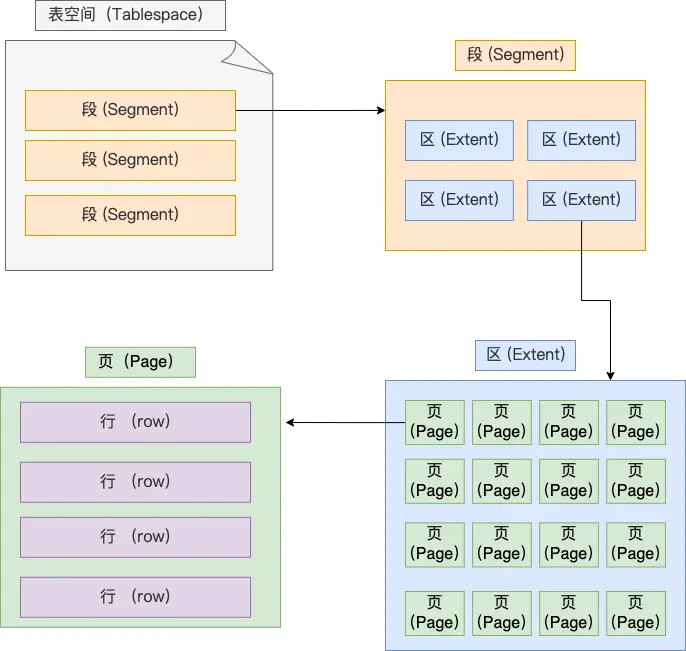
记录是按照行来存储的,但是数据库的读取并不以 行 为单位,否则一次读取(也就是一次 I/O 操作)只能处理一行数据,效率会非常低。因此,InnoDB 的数据是按 页 为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个行记录从磁盘读出来,而是以页为单位,将其整体读入内存。默认每个页的大小为 16KB,也就是最多能保证 16KB 的连续存储空间。
页是 InnoDB 存储引擎磁盘管理的最小单元,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
页的类型有很多,常见的有数据页、undo 日志页、溢出页等等。数据表中的行记录是用 数据页 来管理的,数据页的结构这里我就不讲细说了,之前文章有说过,感兴趣的可以去看这篇文章:换一个角度看 B+ 树
总之知道表中的记录存储在「数据页」里面就行。
InnoDB 存储引擎是用 B+ 树来组织数据的。B+树中每一层都是通过双向链表连接起来的,如果是以页为单位来分配存储空间,那么链表中相邻的两个页之间的物理位置并不是连续的,可能离得非常远,那么磁盘查询时就会有大量的随机I/O,随机 I/O 是非常慢的。
解决这个问题也很简单,就是让链表中相邻的页的物理位置也相邻,这样就可以使用顺序 I/O 了,那么在范围查询(扫描叶子节点)的时候性能就会很高。
即在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
表空间是由各个段(segment)组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段等。
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合,之前讲事务隔离 (opens new window)的时候就介绍到了 MVCC 利用了回滚段实现了多版本查询数据。
2.2 InnoDB 行格式
行格式就是一条记录的存储结构。InnoDB 提供了 4 种行格式,分别是 Redundant、Compact、Dynamic 和 Compressed 行格式。
2.3 COMPACT 行格式
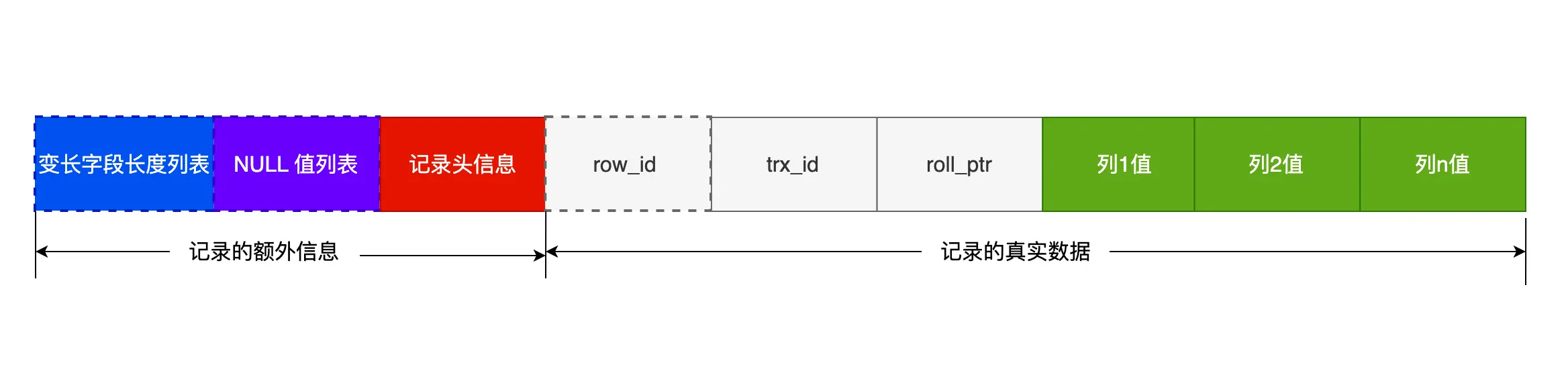
2.3.1 额外数据
2.3.1.1 变长字段长度列表
2.3.1.2 NULL 值列表
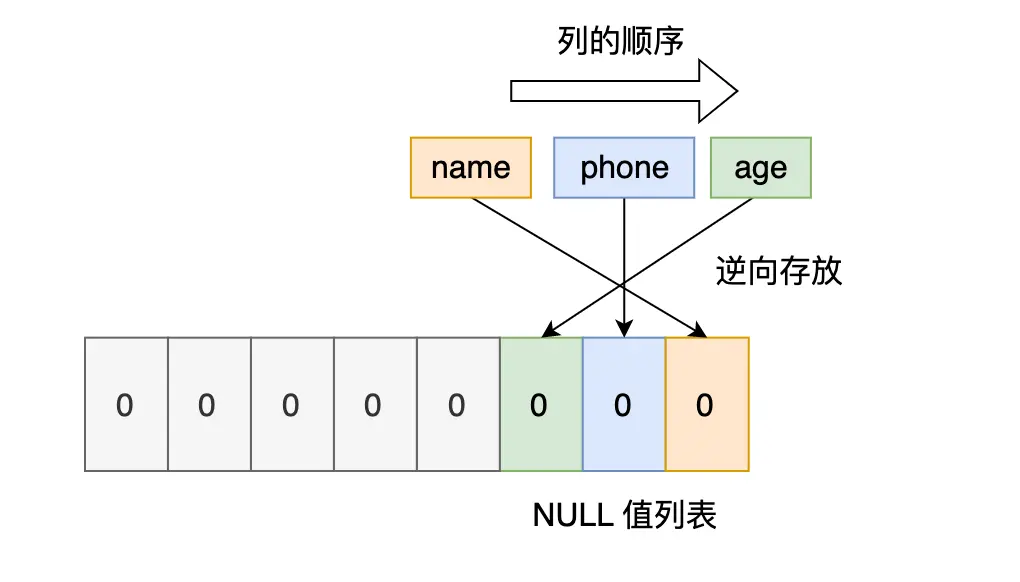
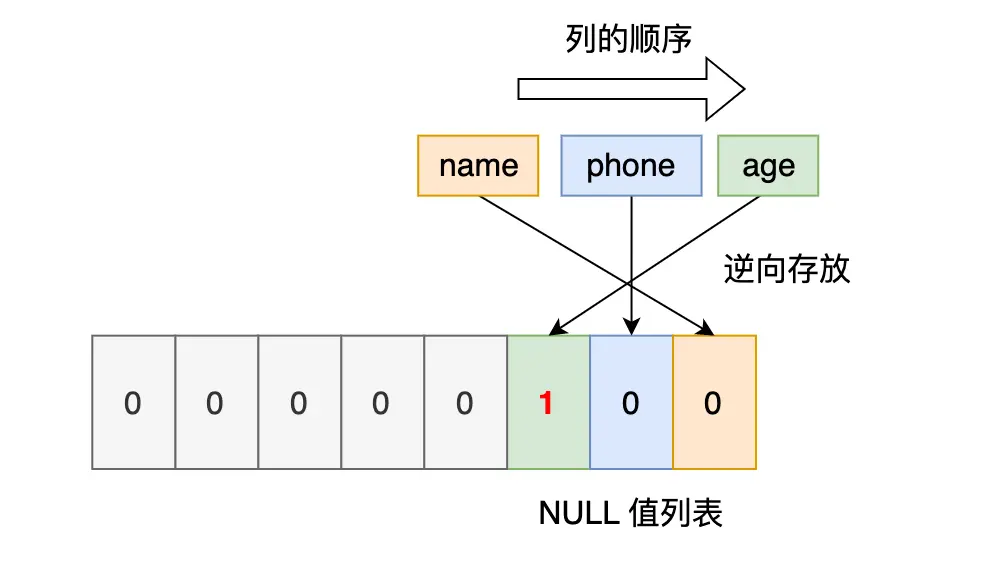
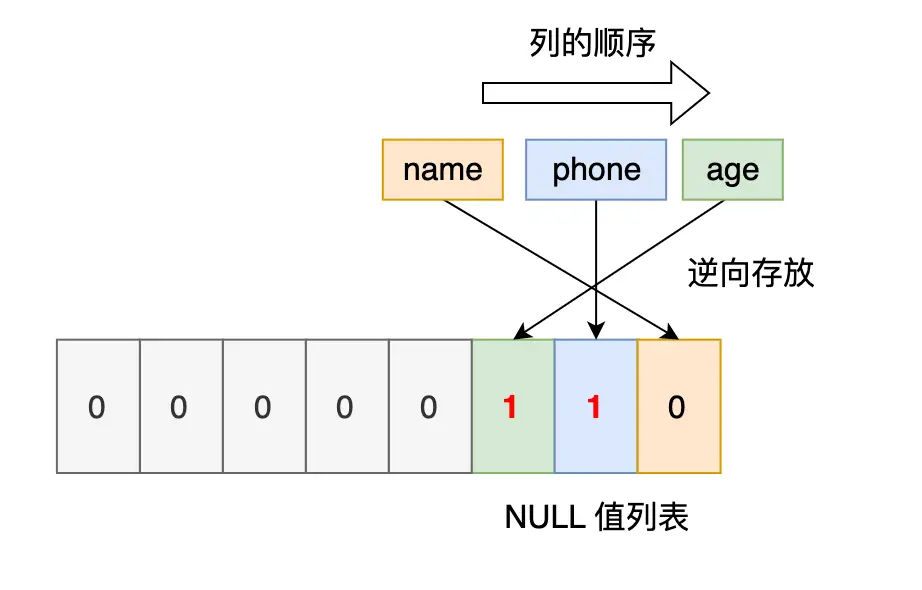
表中的某些列可能会存储 NULL 值,如果把这些 NULL 值都放到记录的真实数据中会比较浪费空间,所以 Compact 行格式把这些值为 NULL 的列存储到 NULL 值列表中。
如果存在允许 NULL 值的列,则每个列对应一个二进制位(bit),二进制位按照列的顺序 逆序排列。
- 二进制位的值为 1 时,代表该列的值为 NULL。
- 二进制位的值为 0 时,代表该列的值不为 NULL。
以 user 表的这三条记录作为例子: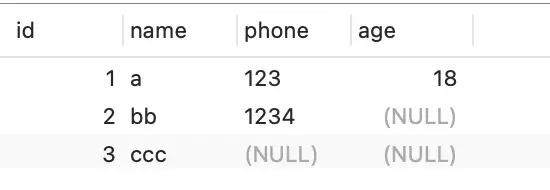
表行格式如下: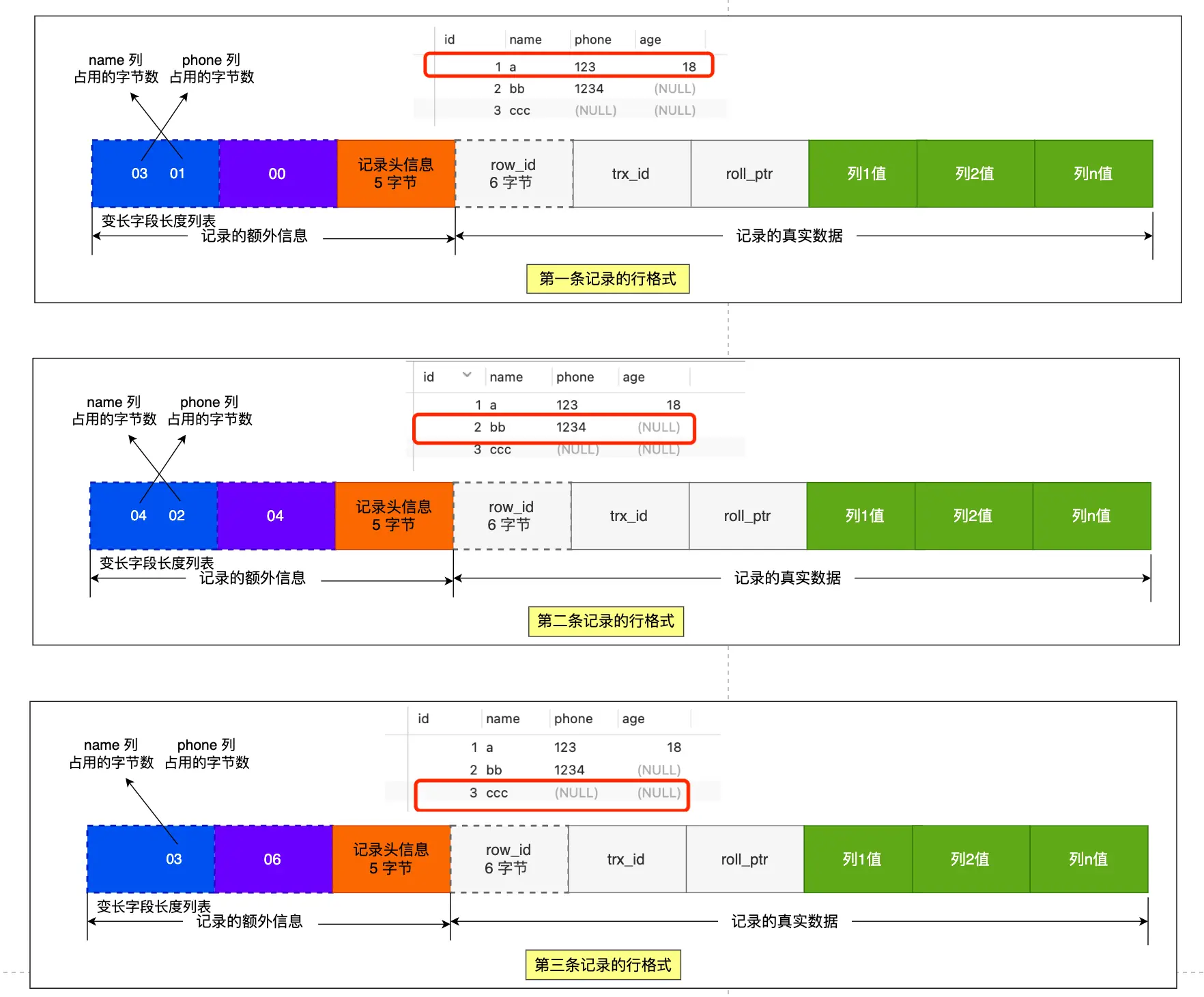
当数据表的字段都定义成 NOT NULL 的时候,这时候表里的行格式就不会有 NULL 值列表了。
记录头信息
- delete_mask: 标识此条数据是否被删除。从这里可以知道,执行 detele 删除记录的时候,并不会真正的删除记录,只是将这个记录的 delete_mask 标记为 1。
- next_record: 下一条记录的位置。从这里可以知道,记录与记录之间是通过链表组织的。在前面我也提到了,指向的是下一条记录的「记录头信息」和「真实数据」之间的位置,这样的好处是向左读就是记录头信息,向右读就是真实数据,比较方便。
- record_type: 表示当前记录的类型,0 表示普通记录,1 表示 B+树非叶子节点记录,2 表示最小记录,3 表示最大记录。