Network System
1.零拷贝
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的磁盘高速缓存区,可以有效的减少磁盘的访问次数。
1.1 为什么有 DMA 技术
DMA(direct memory access, 直接存储器存取)
1.2 传统文件传输的弊端
1.3 优化文化传输性能
1.4 实现零拷贝
1.4.1 mmap + write
read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len); // 替换 read(file, tmp_buf, len);
write(sockfd, buf, len);mmap() 系统调用函数会直接把内核缓冲区里的数据 映射到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
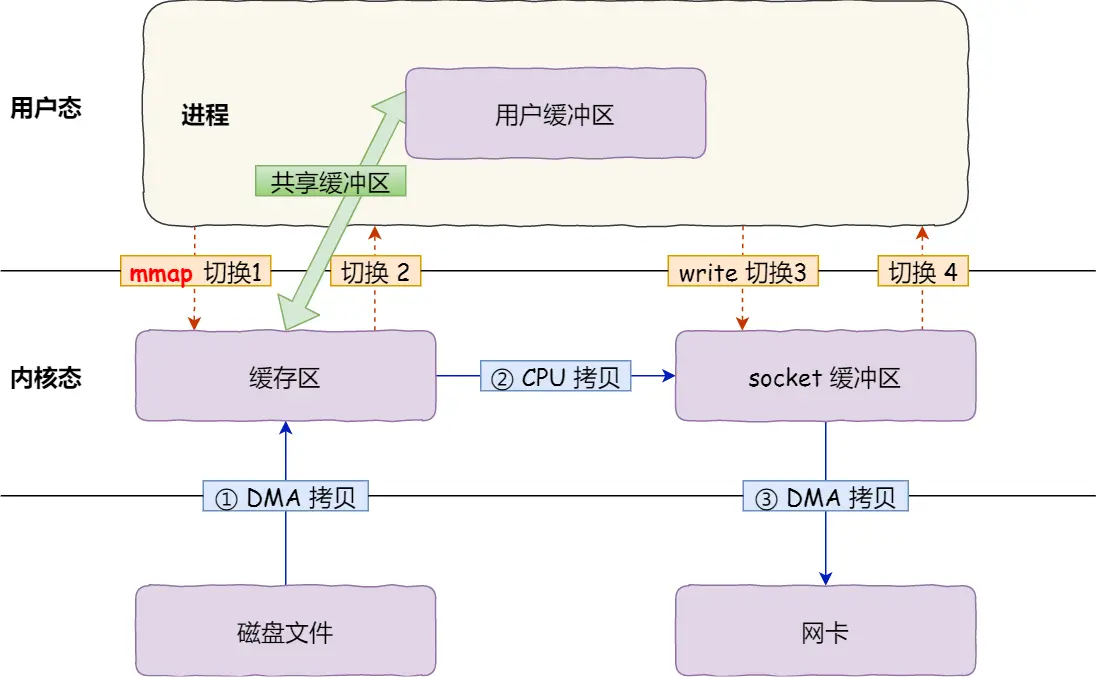
具体过程如下:
应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里。接着,应用进程跟操作系统内核 共享 这个缓冲区;
应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
1.4.2 sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:
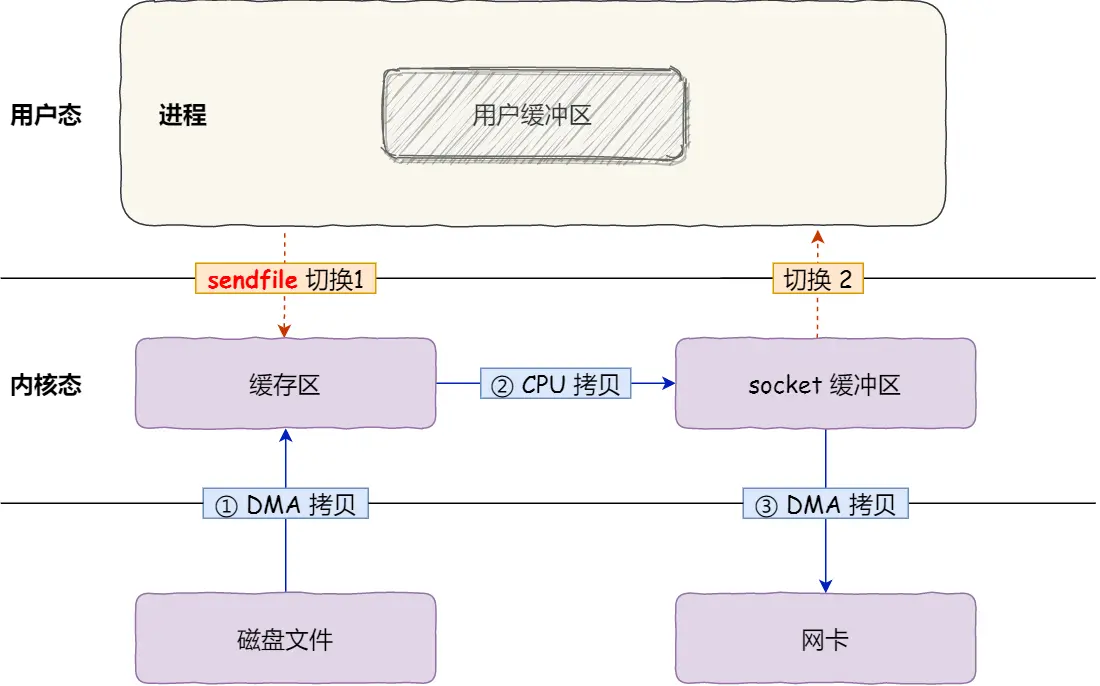
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
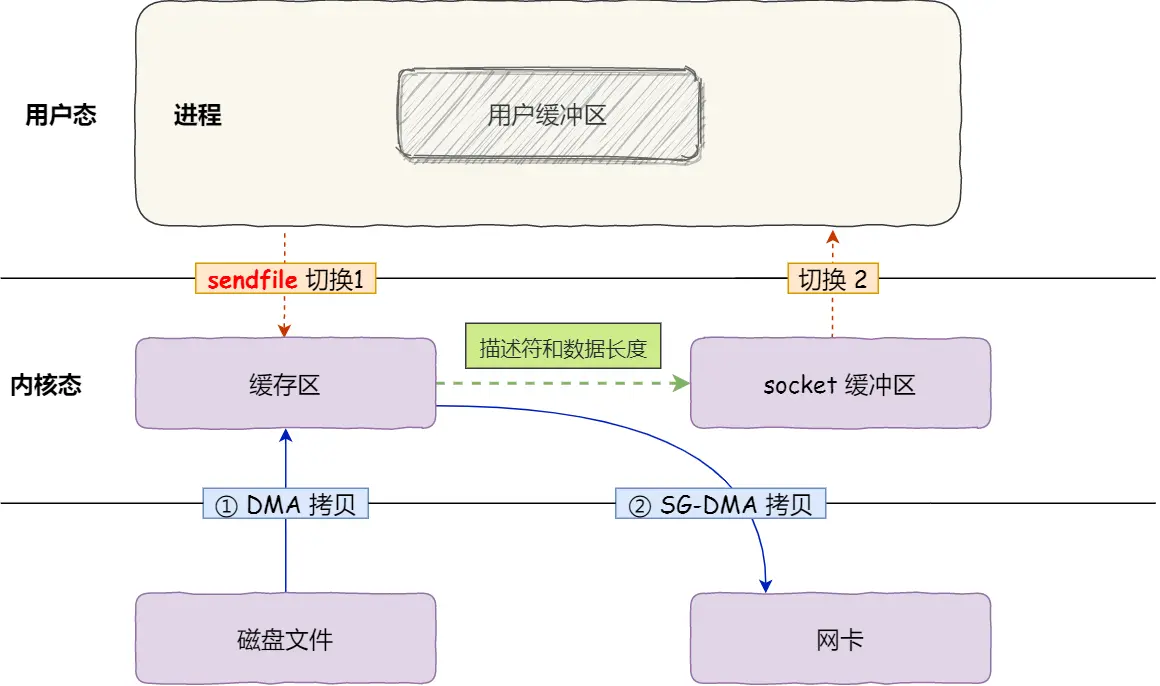
这就是所谓的零拷贝(Zero-copy)技术,因为没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
1.4.3 where use
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
另外,Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
http {
...
sendfile on
...
}sendfile 配置的具体意思:
- 设置为 on 表示,使用零拷贝技术来传输文件:sendfile ,这样只需要 2 次上下文切换,和 2 次数据拷贝。
- 设置为 off 表示,使用传统的文件传输技术:read + write,这时就需要 4 次上下文切换,和 4 次数据拷贝。 当然,要使用 sendfile,Linux 内核版本必须要 2.1 以上的版本。
1.5 PageCache 的作用
1.6 如何实现大文件传输
1.7 总结
2.I/O 多路复用:select/poll/epoll
2.1 最基本的 Socket 模型
要想客户端和服务器能在网络中通信,那必须得使用 Socket 编程,它是进程间通信里比较特别的方式,特别之处在于它是可以跨主机间通信。创建 Socket 的时候,可以指定网络层使用的是 IPv4 还是 IPv6,传输层使用的是 TCP 还是 UDP。
服务端首先调用 socket() 函数,创建网络协议为 IPv4,以及传输协议为 TCP 的 Socket ,接着调用 bind() 函数,给这个 Socket 绑定一个 IP 地址和端口,绑定这两个的目的是什么?
- 绑定端口的目的:当内核收到 TCP 报文,通过 TCP 头里面的端口号,来找到应用程序,然后把数据传递给我们;
- 绑定 IP 地址的目的:一台机器是可以有 多个 网卡的,每个网卡都有对应的 IP 地址,当绑定一个网卡时,内核在收到该网卡上的包,才会发给我们;
3.高性能网络模式:Reactor 和 Proactor
3.1 Reactor
3.1.1 单 Reactor 单进程/线程
3.1.2 单 Reactor 多进程/多线程
3.1.3 多 Reactor 多进程/线程
3.2 Proactor
Reactor 是非阻塞同步网络模型 Proactor 是异步网络模型
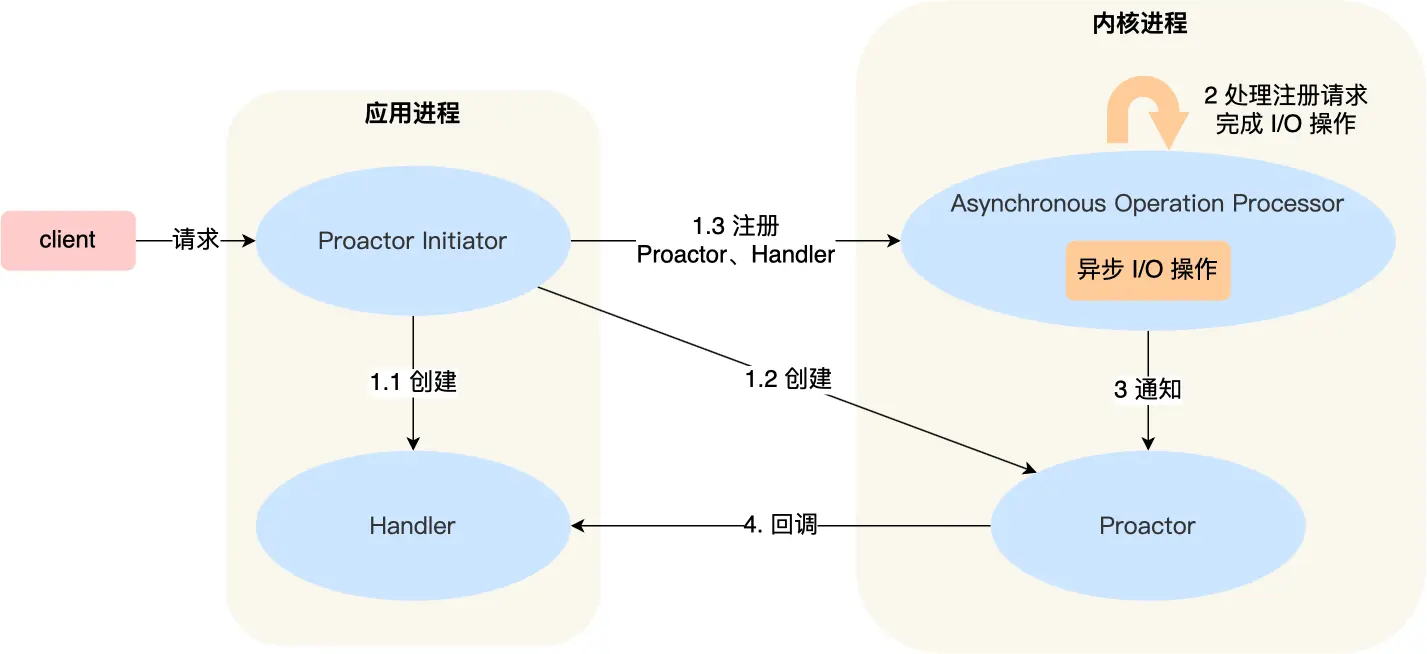
Proactor 模式的工作流程: